一.引言
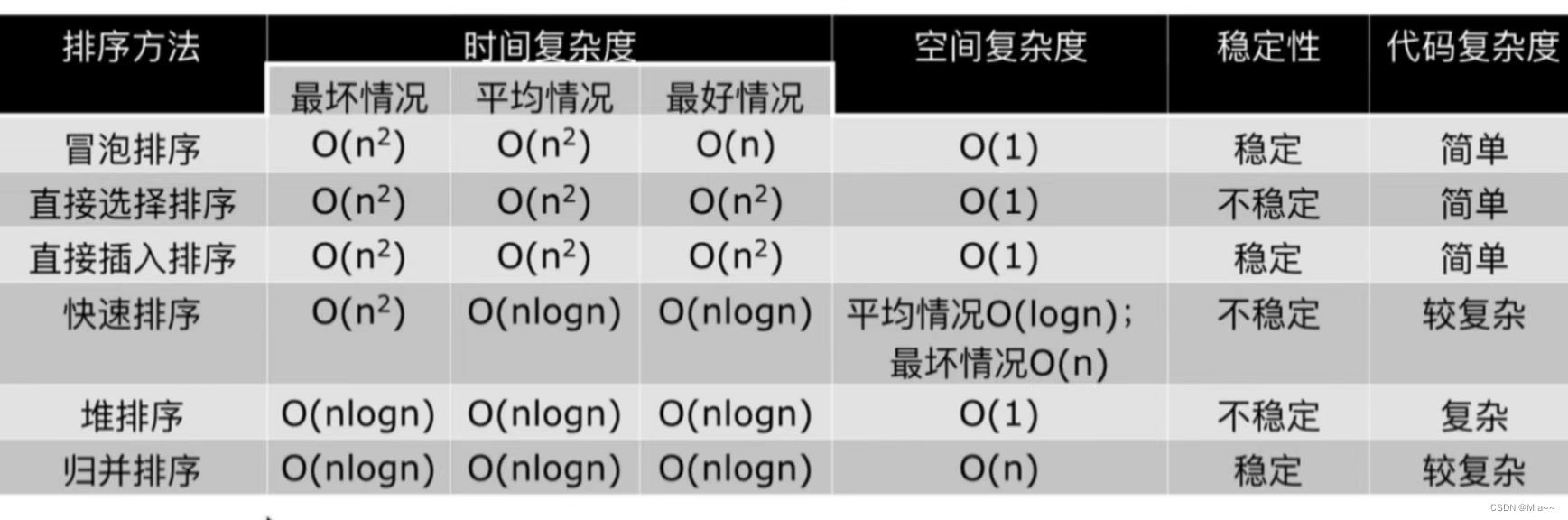
继承 Comparator 实现 PriorityQueue 并且添加元素后,遍历 PriorityQueue 发现元素乱序,于是开始踩坑之旅。首先初始化一个容量为 20 的 PriorityQueue 并添加元素 :
val scoreQueue = new PriorityQueue[(String, String, Double)](20,
new Comparator[(String, String, Double)]() {
override def compare(c1: (String, String, Double), c2: (String, String, Double)): Int =
if (c2._3 - c1._3 > 0) 1
else if (c2._3 - c1._3 < 0) -1
else 0
})其中元祖分别代表用户,商品以及用户对商品的喜好程度 :
scoreQueue.offer("A", "product", -2.38064E-5)
scoreQueue.offer("B", "product", 0.0165529)
scoreQueue.offer("C", "product", 0.01504692)
scoreQueue.offer("D", "product", 0.011048)
scoreQueue.offer("E", "product", 0.0164001)
scoreQueue.offer("F", "product", 0.0164731)二.错误用法
PriorityQueue 优先队列使用前认为他是默认实现排序的,遂直接 foreach 打印发现并不保序:
scoreQueue.asScala.foreach(x => println(x))
B 是最大的排在第一,但是从 E 开始顺序就不对了,而且 A 是负数居然排在正数前面 :
(B,product,0.0165529)
(E,product,0.0164001)
(F,product,0.0164731)
(A,product,-2.383506137528304E-5)
(D,product,0.011048)
(C,product,0.01504692)三.正确用法
PriorityQueue 如果想要获得保序的结果需要使用 poll 方法,该方法会弹出最大元素
(0 until scoreQueue.size()).foreach(_ => {
println(scoreQueue.poll())
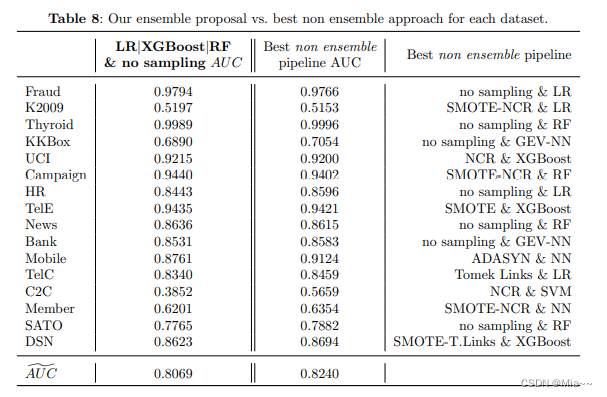
})四.原因分析
之所以 foreach 会乱序是因为 PriorityQueue 并不是基于数组排序而是基于堆 Heap 实现,所以针对这6个数据其存储样式为一个完全二叉树,采用层序遍历时,遍得到了上面不保序的错误结果:
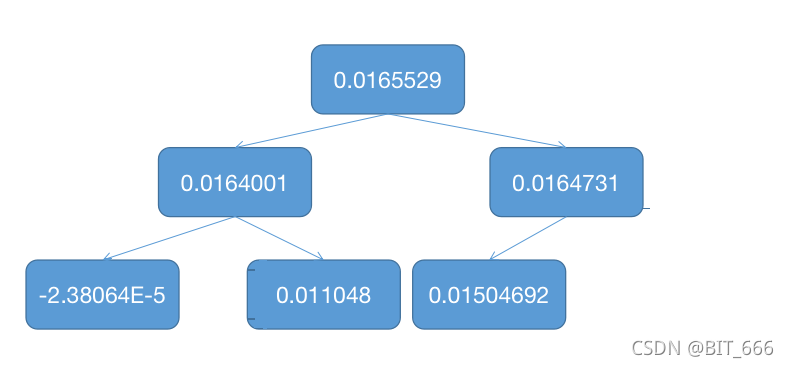
其源码中针对添加元素和删除元素的操作也是基于堆的方案实现,通过添加的索引与父节点 or 子节点比较大小随后交换位置,达到 offer 添加或删除 poll 的操作,从而完成堆的更新。
private void siftUpUsingComparator(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
} private void siftDownComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>)x;
int half = size >>> 1; // loop while a non-leaf
while (k < half) {
int child = (k << 1) + 1; // assume left child is least
Object c = queue[child];
int right = child + 1;
if (right < size &&
((Comparable<? super E>) c).compareTo((E) queue[right]) > 0)
c = queue[child = right];
if (key.compareTo((E) c) <= 0)
break;
queue[k] = c;
k = child;
}
queue[k] = key;
}更多使用方法可以参考 API:PriorityQueue (Java Platform SE 8 ) 和源码